Claude Code ソースコード解説シリーズ 第3章: プロンプト構築
Claude Code が system prompt、記憶、ランタイムコンテキストを毎ターンどう組み立てるかを説明します。
『Claude Code ソースコード解析シリーズ』第3章|プロンプトの組み立て
前回は query.ts の ReAct ループを取り上げ、Claude Code が「判断 → ツール呼び出し → 結果の埋め戻し → 次のターン」を繰り返す仕組みを見てきました。
ここで、すぐに新たな疑問が湧いてきます。
各ターンでモデルを呼び出す前、Claude Code はいったいモデルに何を見せているのか?
多くの人がエージェントを書くとき、まずはこんな素朴な発想から始めるものです。
十分に強力な system prompt を1つ書いて、
「あなたはプログラミングアシスタントである」「ルールを守れ」「ツールを呼び出せる」
と指示すれば、Claude Code のようなものが作れるのではないか?この考え方は間違いではありません。しかし、それはまだ最初の層に触れたに過ぎません。
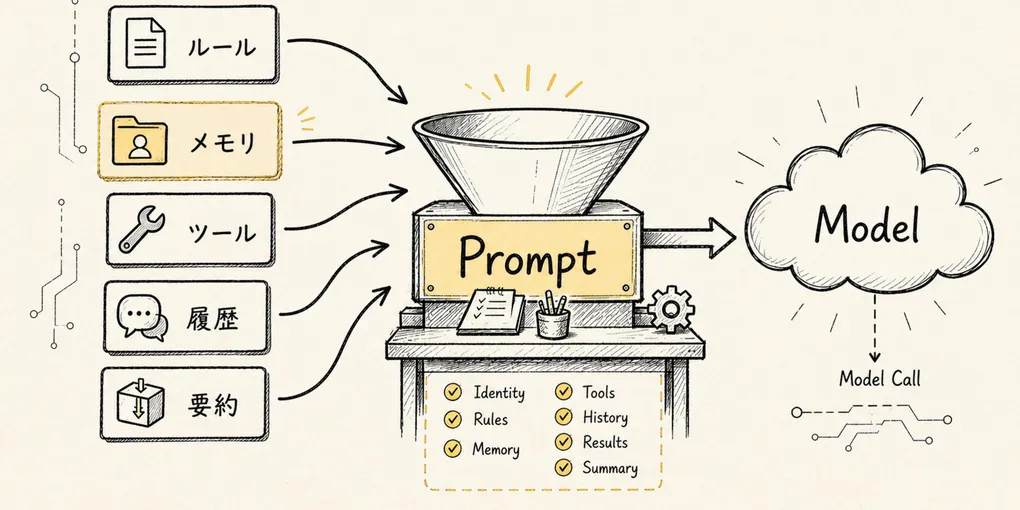
本物の Claude Code は、固定された1つのプロンプトで動いているわけではないのです。モデルを呼び出すたびに、毎回こまごまと情報をかき集めています。基本となる役割定義、システムルール、現在のモード、プロジェクトメモリ、ユーザー設定、Git の状態、ツール仕様、Skill の説明、MCP ケイパビリティ、過去のメッセージ、ツール実行結果、圧縮された要約、そしてユーザーが直近で入力した質問——これらすべてを再構成してからリクエストを送ります。
つまり、この章で答えるべき問いは、次のようなものではありません。
Claude Code のプロンプトには何が書かれているのか?
そうではなく、こうです。
Claude Code は実行時に、複数のソースから得られるコンテキストをどのように組み合わせて、モデルが理解し、行動でき、かつ暴走しない入力へと仕上げているのか?
一言でまとめましょう。
Claude Code のプロンプトは静的なテンプレートではない。それは一種の「プロンプトランタイム」である。システムプロンプトを優先度に応じて選び、メモリを階層に沿って読み込み、ターンごとに動的コンテキストを注入し、ツールの結果を次のターンのメッセージへ埋め戻す。
まずは次の図で全体像をつかんでください。
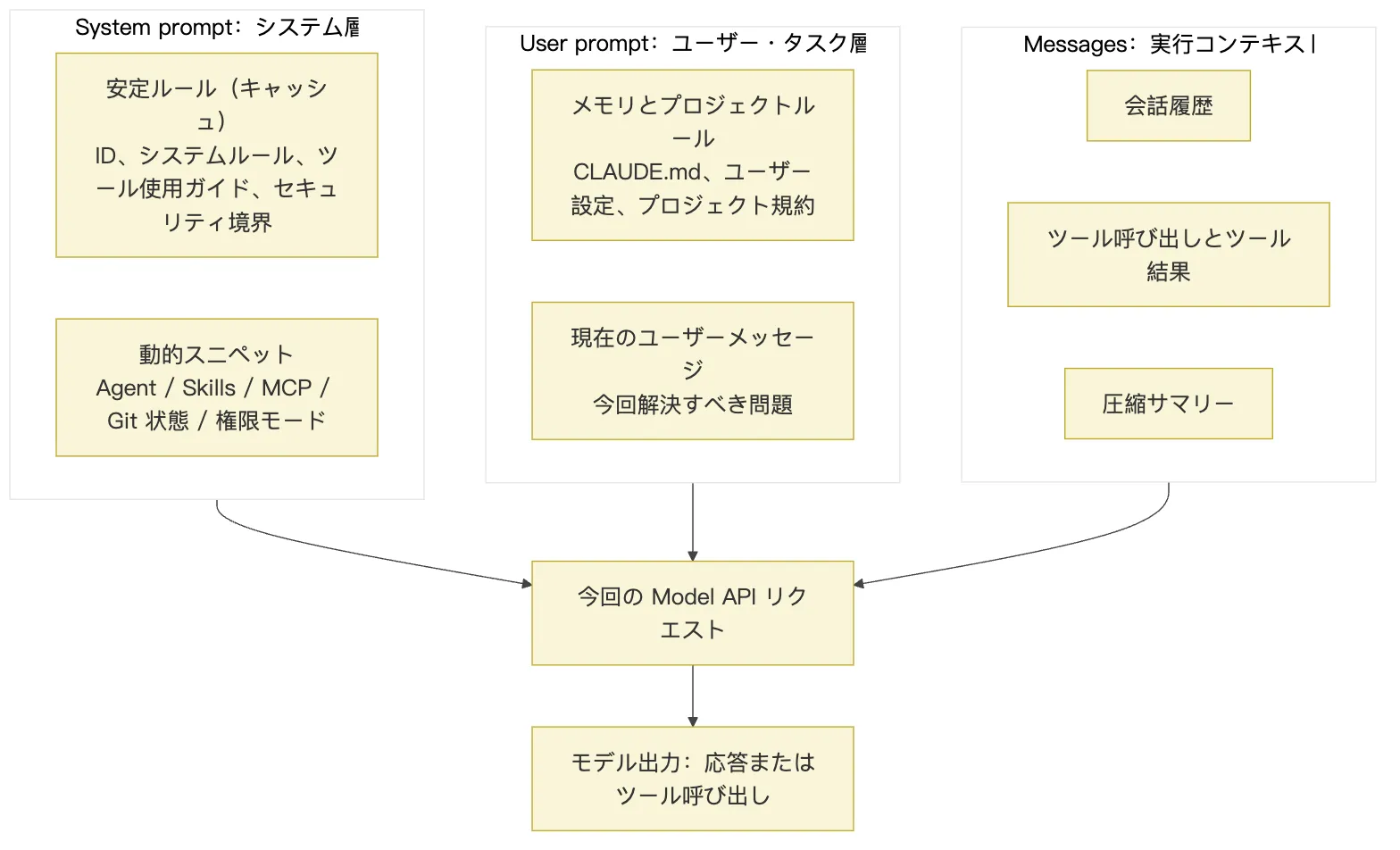
この図が示しているのは、一見すると1本のプロンプトに見えるものが、実際には「安定セグメント」「動的セグメント」「メモリセグメント」「現在のユーザーメッセージ」「履歴メッセージ」に切り分けられているということです。プロンプトランタイムが本当に管理しているのは「文案の書き方」ではなく、何が何を上書きするか、どの順番でコンテキストに入れるか、何がキャッシュ可能で何が毎ターン必ずリフレッシュされるかなのです。
1. 単一の巨大プロンプトで済ませられない理由
実践的な場面を想像してみよう。
ユーザーがプロジェクトルートでこう入力する。
このプロジェクトのテストがなぜ失敗しているのか調べて、修正してほしい。ありきたりなプロンプトを一つ渡しただけなら、モデルが知り得るのはせいぜいこの程度だ。
あなたはプログラミングアシスタントです。
ユーザーがコードを修正するのを手伝ってください。
簡潔に回答してください。話にならない。
モデルが本当に必要としている情報は以下のようなものだ。
どのプロジェクトか?
カレントディレクトリはどこか?
そのプロジェクトに独自の開発規約はあるか?
ユーザー固有の設定や好みはあるか?
現在 Git のワーキングツリーにコミットされていない変更があるか?
利用可能なツールは何か?
どのコマンドに確認が必要か?
これまでのやり取りで、どのファイルを読み、どのテストを実行したか?
コンテキストが長すぎる場合、どの履歴がすでに要約として圧縮されたか?これらの情報はテンプレートにハードコードできるものではなく、実行時になければ手に入らない。
Git の状態は変わり、今日の日付も変わり、ツール呼び出しの結果も変わり、ユーザーの入力も変わる。カレントディレクトリにある CLAUDE.md だって、別のプロジェクトではまったく異なる内容だろう。
つまり Claude Code が直面しているのは「どうやって万能プロンプトを書くか」ではなく、よりエンジニアリング的な問いなのだ。
モデルを呼び出すたびに、一体どの情報を詰め込むべきか? どんな順序で並べるべきか? 情報が衝突したら、どれを優先するか? 長すぎるなら、何から削るか? キャッシュできるなら、その境界をどこに引くか?
これこそが Prompt Runtime の存在理由である。
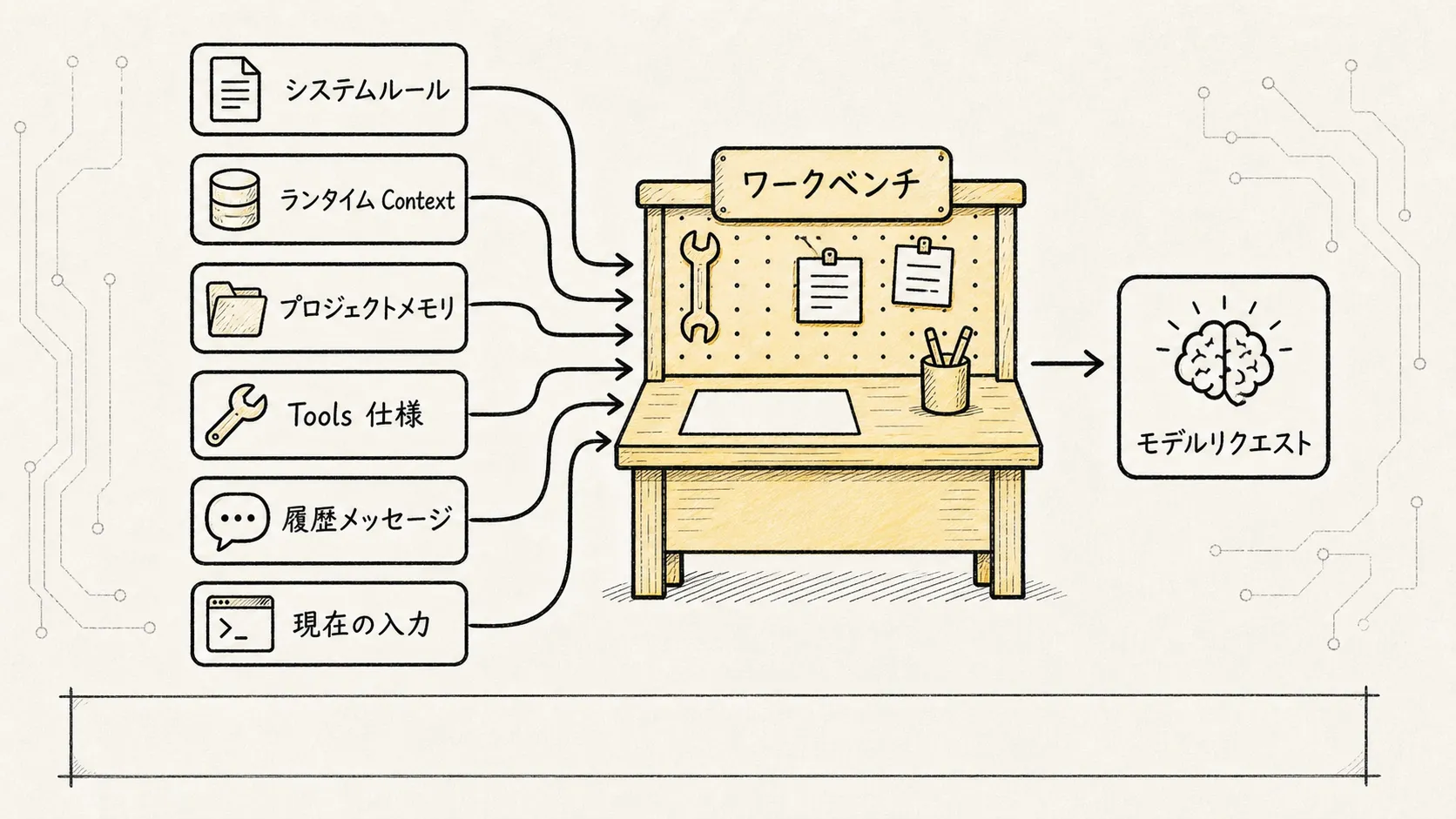
2. モデルへの1回の入力に入っているのは、システムプロンプトだけではない
まずはいくつかの概念を切り分けておく。後々の混同を防ぐためだ。
普段私たちは、モデルに与えるものすべてを「プロンプト」と呼びがちだ。しかし Claude Code のようなエージェントシステムでは、1回のモデル入力は少なくとも以下の種類に分けられる。
system prompt システムレベルの動作ルール
system context システム環境コンテキスト(Git の状態など)
user context ユーザーとプロジェクトのコンテキスト(日付、CLAUDE.md など)
messages ユーザーメッセージ、モデルの応答、ツール呼び出し、ツールの結果
toolUseContext 現在利用可能なツールとそのスキーマ、権限、実行コンテキストこれらはそれぞれ責務が異なる。
system prompt はモデルの操作マニュアルだ。「お前は何者か、どう振る舞うか、どんな境界があるか」を伝える。
user context はユーザーとプロジェクトが与える長期的な制約で、たとえば「このプロジェクトは pnpm を使う」「コミットメッセージは日本語で」「生成ファイルを直接書き換えるな」といったものだ。
system context は実行環境の情報で、現在の Git ブランチ、ワークスペースの変更、直近のコミット、現在のユーザー名などが含まれる。
messages は現場の帳簿であり、そのタスクの中で何が起きたかを記録する。ユーザーが何を言ったか、モデルがどのツールを呼んだか、ツールが何を返したか、といった履歴だ。
toolUseContext は、このターンでモデルが使える「手足」を伝える。Read、Edit、Bash、Grep、Task、MCP ツール、Skill ツールなどだ。
したがって、Claude Code の組み立てロジックは次のように簡略化できる。
安定したシステムルール
+ 現在の実行環境
+ ユーザー / プロジェクトの記憶
+ ツール能力の説明
+ 過去のメッセージとツール結果
+ 現在のユーザー入力
=> 今回のモデルリクエスト「プロンプトの文言が優れているかどうか」だけを議論するのは一面的だ。エージェントの安定性を本当に左右するのは、これらの情報がいかに整理され、上書きされ、キャッシュされ、圧縮されるかである。どんなに華麗なシステムプロンプトを書いても、ツールの結果が正しく埋め戻されなければ、モデルはやはり途中でちぐはぐになる。
3. 第一層:system prompt は単なる文字列連結ではなく、優先度に基づく選択である
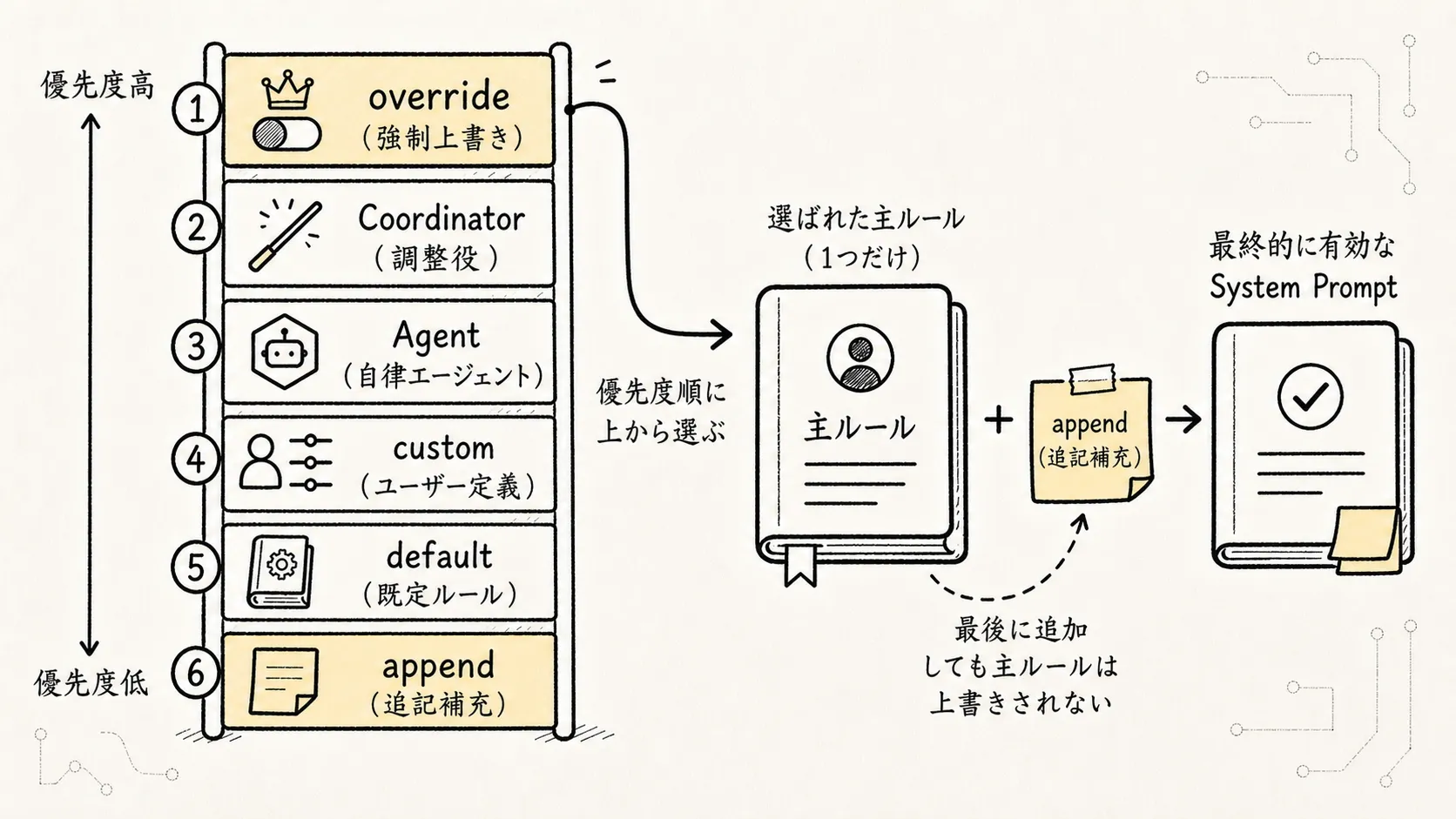
まず system prompt の優先度を見ていく。抽象化すると次のような選択チェーンになる:
0. overrideSystemPrompt 全プロンプトを完全に置き換える(例:loop モード)
1. Coordinator prompt コーディネーターモード有効時に使用
2. Agent prompt カスタム Agent 定義のプロンプト
3. customSystemPrompt --system-prompt で指定
4. defaultSystemPrompt 標準のデフォルト Claude Code プロンプト
5. appendSystemPrompt 常に末尾に追加これらの名前をひとつずつ紐解いていく。これらは単一の設定項目群ではなく、Claude Code が effective system prompt を組み立てる際に用意された複数の「エントリポイント」である:
| 名称 | 意味 | 出所 |
|---|---|---|
overrideSystemPrompt | 最優先の内部オーバーライド。これが存在する場合、デフォルト・カスタム・Agent のプロンプト選択ロジックを一切経由せず、メインのシステムプロンプトをこの内容で直接置き換える。 | 一般ユーザ向けの CLI 引数ではない。通常は上位の内部呼び出し元(例:loop / fork / バックグラウンドタスクモード)が Agent や QueryEngine を呼ぶ際に、あらかじめレンダリング済みのシステムプロンプトとして渡す。「現在のタスクには別の実行ルールを適用しなければならない」という要件に対応する。 |
Coordinator prompt | コーディネーター自身のシステムプロンプト。モデルをマルチ Agent オーケストレーターとして定義し、自らファイルを編集したり全ツールを実行したりするのではなく、タスク分割・worker への割り当て・結果収集・総合判断を中核責務とする。 | Coordinator モード関連モジュールに由来。機能フラグとランタイム設定の両方でコーディネーターモードが有効化された場合にのみ使用される。このモードでは利用可能ツールや worker 記述も併せて変更される。 |
Agent prompt | サブ Agent またはカスタム Agent 専用のシステムプロンプト。その Agent が何に向いているか、どのツールを使えるか、出力はどうあるべきかを定義する。 | Agent 定義に由来。組み込み Agent は getSystemPrompt() で動的に生成。カスタム Agent は通常、ユーザが作成した Agent Markdown / JSON 定義から生成され、その本文がシステムプロンプトとなり、必要に応じて Agent memory 関連のプロンプトが追加される。 |
customSystemPrompt | ユーザが明示的に指定した「デフォルトシステムプロンプトの置き換え」。補足説明ではなく、ユーザが指定した内容でデフォルトの Claude Code プロンプトを上書きする。 | CLI / SDK のエントリポイント由来(例:--system-prompt)。QueryEngineConfig 上では customSystemPrompt?: string として表現される。 |
defaultSystemPrompt | 通常の Claude Code セッションにおける標準のシステムプロンプト。デフォルトの役割、協調方法、ツール使用原則、セキュリティ境界、コードタスクの処理方針などを定義する。 | Claude Code 組み込みのプロンプト構築関数に由来。メインフローは fetchSystemPromptParts() / getSystemPrompt() 相当のロジックを呼び出し、デフォルトのシステムプロンプト断片を取得する。 |
appendSystemPrompt | メインプロンプトの末尾に必ず追加される補足制約。モデルの役割を変更せず、選択済みのメインシステムプロンプトの後ろに追加ルールを付与する。 | CLI / SDK のエントリポイント由来(例:--append-system-prompt)。一部の内部モードが追加説明を自動付与するケースもある。最終的な組み立て時に system prompt 配列の末尾に配置される。 |
つまり、ここでの「ソース」は大きく3つに分類されます。
製品組み込み:defaultSystemPrompt / Coordinatorプロンプト / 組み込みAgentプロンプト
ユーザー設定:customSystemPrompt / appendSystemPrompt
内部実行時:overrideSystemPrompt / 特定の状況で自動付与されるappendSystemPromptソースコードレベルの流れを見ると、より明確になります。通常のメインフローでは、QueryEngine.submitMessage() がまずデフォルトのプロンプト、ユーザーコンテキスト、システムコンテキストを取得し、次のような形で組み立てます。
const systemPrompt = asSystemPrompt([
...(customPrompt !== undefined ? [customPrompt] : defaultSystemPrompt),
...(memoryMechanicsPrompt ? [memoryMechanicsPrompt] : []),
...(appendSystemPrompt ? [appendSystemPrompt] : []),
])このロジックは最も基本的な置き換えルールを表しています。customSystemPrompt があればそれで defaultSystemPrompt を置き換え、なければデフォルトのプロンプトを使い、最後に appendSystemPrompt を追記する、というものです。
しかし、完全な実行時フローでは、その前にまず現在のモードを判定する必要があります。たとえば Coordinator の実行中であれば Coordinator のシステムプロンプトを使うべきですし、特定のカスタム Agent を起動中であれば、その Agent 自身の getSystemPrompt() を使うべきです。また、上位レイヤーから overrideSystemPrompt が渡されている場合は、今回の呼び出しではメインのロール自体を差し替えるということを意味します。
実行ロジックに近い形で図にすると、次のようになります。
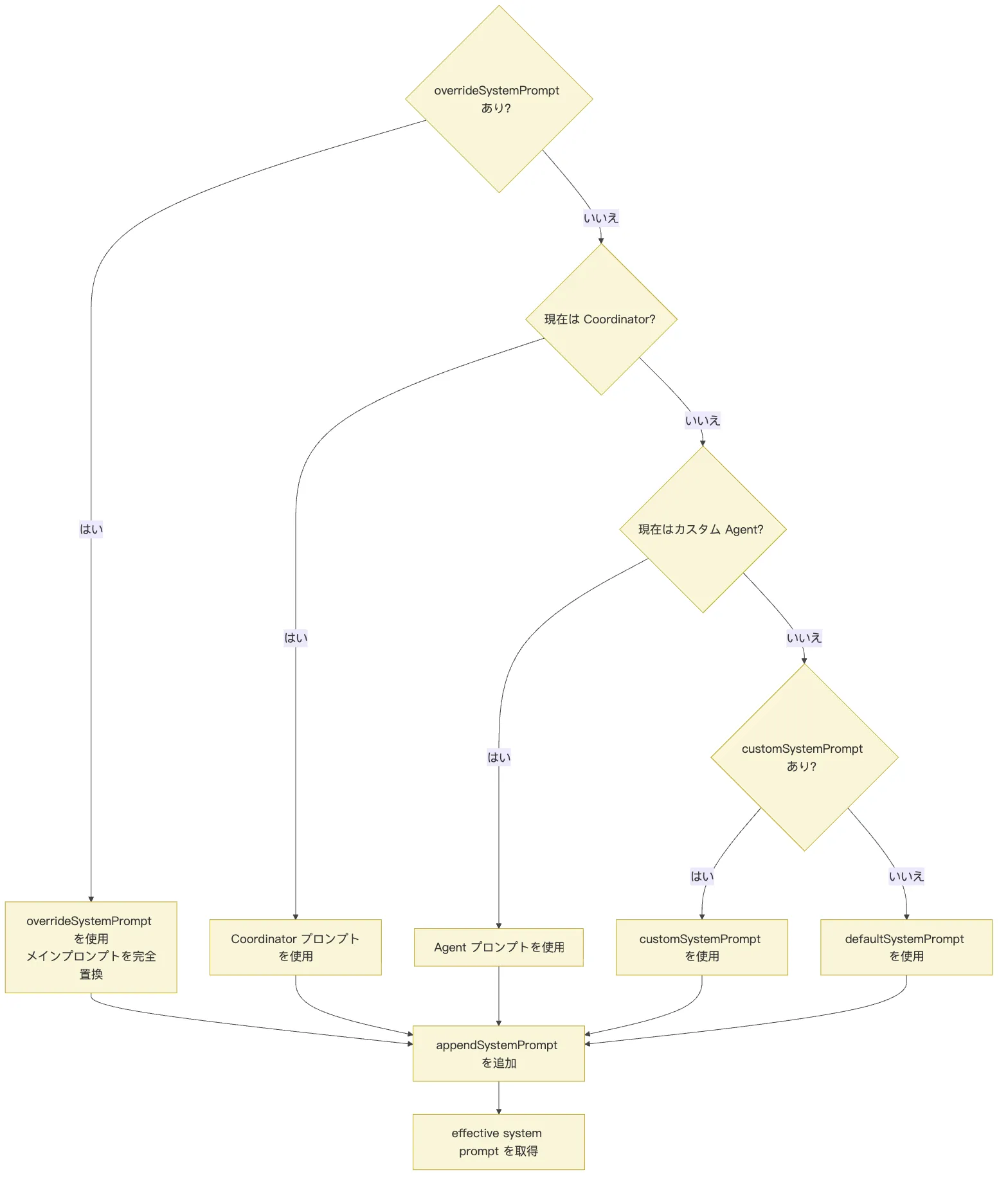
このチェーンが示しているのは一つのことです。
Claude Code は、各種の system prompt をただ闇雲に連結するのではなく、まず現在の実行モードを判定し、その上で「誰がメインプロンプトになるか」を決める。
defaultSystemPrompt は通常セッションのベースプロンプトであり、プログラミングアシスタントとしてのモデルのデフォルト動作を定義する。ユーザーとの協調の仕方、ツールの使い方、コードタスクの処理方法、注意すべき事項などだ。
しかし何らかの特殊モード(たとえば内部 loop モード)に入った場合、overrideSystemPrompt がデフォルトのプロンプトをまるごと置き換える。これは「後ろにちょっとした特殊指示を追加する」のではなく、「操作マニュアルをそっくり差し替える」という動きだ。
現在がマルチエージェント協調モードであれば、Coordinator prompt や Agent prompt がモデルのアイデンティティを再定義する。コーディネーターはタスク分割・スケジューリング・結果統合を担当し、子エージェントは検索・計画・実装・検証のいずれかだけを担うかもしれない。両者がまったく同じシステムプロンプトを共有すべきではない。
customSystemPrompt は、ユーザーや外部呼び出し元に対して上書き用のエントリポイントを提供する。たとえばコマンドライン引数でカスタムのシステムプロンプトを渡し、特定のセッションを特別なルールで動作させるといった使い方だ。
最後に appendSystemPrompt は少し特殊で、メインプロンプトを置き換えず、常に末尾に追記される。必ず補足すべき一時的なルールを入れる場としては適しているが、基盤となる動作規範をこれで代用してはいけない。
この仕組みを一言でいえば、次の三段階だ。
まずメインのアイデンティティを選ぶ
次にメインのルールを選ぶ
最後に補足的な制約を追記する「多数のプロンプト文字列を連結する」方式より安全であり、異なるモード間に明確な境界が生まれる。
小さな例:なぜ override と append は混同してはいけないのか?
デフォルトプロンプトが次のようになっているとする。
あなたは Claude Code で、ユーザーのコードタスクを支援するのが役割です。ユーザーが次のように追記した場合:
今回の回答はより簡潔にしてください。これは appendSystemPrompt に適している。スタイルを補足しているだけで、アイデンティティは変えていないからだ。
しかしシステムが特殊な自動ループモードに入った場合、必要なのはこういう指示だ。
あなたは現在、通常の対話アシスタントではなく、内部ループ実行器です。
構造化された状態のみを出力し、通常の対話は行わないでください。これはデフォルトのプロンプトの末尾に追記できるようなものではない。そうすると「あなたは通常のプログラミングアシスタントです」と「あなたは内部ループの実行者です」という両方の指示をモデルが同時に見ることになり、ルールが相互に汚染されてしまう。
こういうときに使うのが overrideSystemPrompt だ。
優先順位チェーンが解決する本質的な問題は次のとおりである。
複数のソースがモデルの振る舞いを定義しようとするとき、誰が最終的な解釈権を持つのか。
4. 第二層:CLAUDE.md はプロジェクトの記憶であり、単なる説明文書ではない
システムプロンプトは「モデルがデフォルトでどう振る舞うか」を解決するが、現在のプロジェクトのルールまではまだ知らない。
そこで CLAUDE.md の出番だ。
CLAUDE.md は Claude Code にとってのプロジェクト作業指示書と捉えるとよい。人間向けの README ではなく、Agent 向けの動作ルールなのだ。
このプロジェクトはどう起動するのか?
テストコマンドは何か?
コードスタイルは?
変更してはいけないディレクトリは?
PR 説明はどう書くのか?
データベースマイグレーションで注意すべきことは?さらに CLAUDE.md の読み込み順序を整理すると、一連の記憶階層として描ける。
1. 管理記憶 /etc/claude-code/CLAUDE.md
2. ユーザー記憶 ~/.claude/CLAUDE.md
3. プロジェクト記憶 CLAUDE.md、.claude/CLAUDE.md、.claude/rules/*.md
4. ローカル記憶 CLAUDE.local.md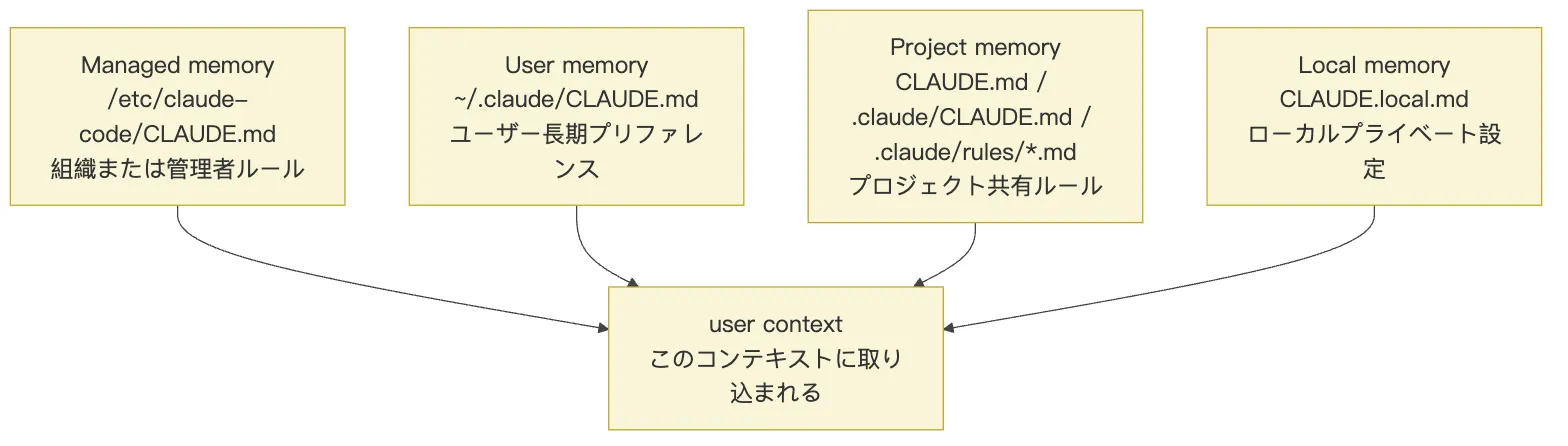
これらの階層はそれぞれ意味が異なる。
管理記憶 は組織または管理者レベルのルールだ。セキュリティポリシー、コードレビュー要件、本番環境への操作禁止など、全社的に遵守すべき制約を置くのに適している。
ユーザー記憶 はユーザー自身の長期的な好みだ。たとえば日本語での説明を好む、特定のテスト習慣を好む、コミットメッセージに特定の形式を好む、といった情報である。
プロジェクト記憶 はプロジェクトレベルのルールで、通常はリポジトリと共にメンテナンスする。このプロジェクト固有のビルド方法、ディレクトリ規約、技術スタックの境界などを Agent に伝える。
ローカル記憶 はローカル固有のプライベートルールで、通常はバージョン管理に含めない。ローカルサービスのポート番号、プライベートパス、一時的なデバッグ習慣など、自分のマシンでのみ成立する情報を置くのに適している。
この階層構造は複雑さを追求したものではなく、ごく現実的な問題を解決するためのものだ。
Agent は組織のルールを守り、ユーザーの好みを尊重し、現在のプロジェクトに適応し、なおかつローカルのプライベート設定をチームに共有してはならない。
これが記憶の階層を分ける理由でもある。組織ルール、ユーザー設定、プロジェクト規約、ローカルのプライベート設定を混在させると、後で衝突が起きたときに、どれを優先すべきか判断できなくなる。
単一の CLAUDE.md だけだと、これらの情報がすべて混ざってしまう。組織ルール、個人の好み、プロジェクト規約、ローカルの一時的な設定が一箇所に詰め込まれ、最終的に衝突しても優先順位がわからない。
階層化することで、Claude Code は記憶システムをガバナンス可能なルールスタックへと変えている。
CLAUDE.md はなぜプロンプトに入るのか
モデル自体はプロジェクトの取り決めを知らないからだ。
たとえばプロジェクトに次のように書かれていたとする。
- pnpm を使い、npm は使わないこと。
- TypeScript ファイルを変更したら必ず pnpm typecheck を実行すること。
- generated/ ディレクトリを手動で編集しないこと。これらのルールがコンテキストに入っていなければ、モデルはごく自然に次のコマンドを実行してしまうだろう。
npm testあるいは生成ファイルを直接編集してしまう。
これはモデルが「賢くない」からではなく、プロジェクトのルールを目にしていないからだ。
CLAUDE.md の価値は、プロジェクトの知識をモデルが見える作業記憶に押し込むことで、最初からそのリポジトリのやり方に従って動作させることにある。
ただし、ここには境界がある。CLAUDE.md は多ければ多いほど良いというものではない。
数万字に及ぶ経緯説明を詰め込むと、モデルはノイズに埋もれ、コストも上がってしまう。そのため Claude Code は記憶の内容に対してサイズ制限、キャッシュ、選択的ロードの仕組みを備えている。さらに高度なサブ Agent では omitClaudeMd を選択することで、読み取り専用の検索や計画のシナリオにおいてプロジェクト記憶を省略し、トークンコストと注意の妨げを抑えることも可能だ。
これは、 CLAUDE.md の本質が「必ず常に全文をプロンプトに含めること」ではないことを示している。
適切なタスクにおいて、適切な階層のプロジェクト記憶をモデルに注入すること——これが核心である。
5. 第三層:動的コンテキストは毎ターン再評価される
ここまでで、システムプロンプトとプロジェクトメモリが揃った。しかし Claude Code には、さらにランタイムの情報が必要になる。
典型的な動的コンテキストは以下のとおりである。
現在の日付
現在の作業ディレクトリ
現在の Git ブランチ
git status
最新のコミット
現在のユーザー名
このターンで利用可能なツール
MCP サーバーが公開しているツール
検出された Skills
パーミッションモード
圧縮サマリーこれらの情報を CLAUDE.md に書き込むのは適切ではない。
Git の状態は刻々と変化し、日付は日替わりで変わり、ツール一覧は MCP 接続に応じて変動し、Skill も実行中にホットリロードされうる。
そのため Claude Code は、getSystemContext() や getUserContext() といった経路を通じて、実行時にコンテキストを生成する。
ざっくりとしたイメージは次のとおりだ。
getSystemContext()
→ Git の状態、ブランチ、最新コミット、環境情報を読み取る
→ システムレベルのコンテキストを形成する
getUserContext()
→ 日付、CLAUDE.md、ユーザー/プロジェクトメモリを読み取る
→ ユーザーレベルのコンテキストを形成するこれには二つの利点がある。
第一に、動的な情報が静的なプロンプトを汚染しない。
defaultSystemPrompt は安定したまま保たれ、Git 状態のような変動の激しい情報は個別に注入される。キャッシュが効きやすくなり、どの内容が変わったかの判断もしやすくなる。
第二に、毎ターンのモデル呼び出しで、その時点でもっとも関連性の高い情報を参照できる。
1 ターン目ではモデルはまだファイルを読んでおらず、より多くの全般的なルールやツールの説明を必要とする。5 ターン目にもなれば、テストのエラーと該当するソースコードをすでに取得しており、メッセージ履歴とツール結果のほうが重要になる。コンテキスト圧縮が発生した場合、古い履歴はサマリーに置き換えられ、モデルは次のターンで圧縮後の状態を見ることになる。
つまり、Claude Code のコンテキスト組み立ては一度きりの処理ではなく、ループの中で継続的に行われる動作なのだ。
ユーザー入力
→ 今回のターン用コンテキストを構築
→ モデルを呼び出す
→ モデルがツールを要求
→ ツール結果を messages に書き戻す
→ 圧縮が必要かチェック
→ 次のターンでコンテキストを再構築これは前回の ReAct メカニズムと綺麗につながる。プロンプトの組み立ては Agent Loop の外側にあるのではなく、Loop の各ターンの入り口に位置しているのである。
6. cached:安定セグメントと動的セグメントを分離する理由
背景には、きわめて現実的な問題がある。Agent はモデルを頻繁に呼び出すため、ラウンドごとにまったく同一の長大なシステムプロンプトを毎回再計算・再課金・再処理していては、コストもレイテンシも跳ね上がってしまう。
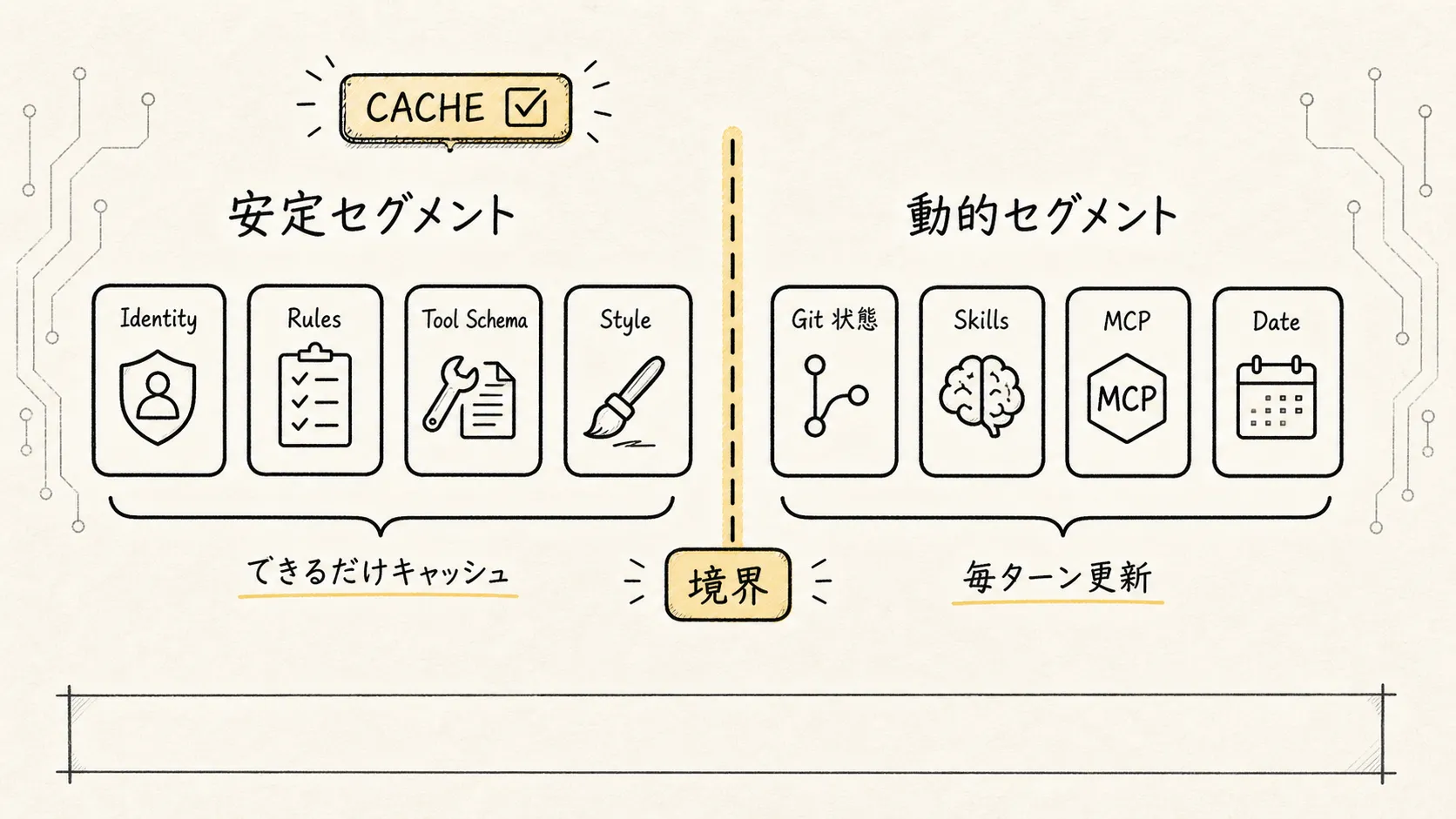
そこで Claude Code は、安定セグメントをなるべく前方に配置し、Prompt Cache にヒットしやすくしている。
安定セグメントには、通常次のようなものが含まれる。
役割の説明
システムルール
タスク実行ガイドライン
操作安全ガイドライン
ツール使用ガイドライン
トーンとスタイル
出力効率の要件これらはひとつのセッション内では基本的に変化しないため、キャッシュに適している。
一方、動的セグメントには次のようなものが含まれる。
Agent ツールコンテキスト
Skills コンテキスト
CLAUDE.md の読み込み結果
MCP サーバー命令
Git ステータス
現在日付これらは変化しやすいため、安定セグメントとは分離しておく必要がある。
キャッシュ境界は次のように図示できる。

ソースコードには SYSTEM_PROMPT_DYNAMIC_BOUNDARY という設計が登場する。ざっくり言えば、次のような考え方だ。
この線より前はなるべく安定させ、キャッシュしやすくする
この線より後は変化しうるため、ラウンドごとにリフレッシュするこの境界がきわめて重要である。
変動の大きい情報を安定セグメントに混入させると、たとえば動的な Skill リストをツール説明に直接埋め込んでしまった場合、Skill リストが変わるたびにシステムプロンプト全体のキャッシュが無効化される。見た目には小さなリストをひとつ変えただけでも、実際にはラウンドごとに数千、ときには数万トークンが再処理される可能性がある。
つまり Prompt Runtime は、単に「モデルにより多くの情報を与える」だけの仕組みではない。コストも制御するのだ。
安定コンテンツはなるべく安定させる
動的コンテンツは個別に隔離する
キャッシュ無効化には明確な境界を設けるこれは Claude Code とトイ Agent を分かつ違いでもある。トイ Agent は「動くかどうか」だけを気にするが、成熟した Agent は「20ラウンド、50ラウンド、100ラウンドと続いたときに、コストとレイテンシがまだ許容範囲かどうか」まで気にする。
複雑なタスクでは、キャッシュのヒットとミスの差が複数回の呼び出しを通じて拡大されていく。ユーザーが感じるのは小さな最適化ではなく、タスク全体がスムーズに進むかどうかである。
7. user prompt:現在の問題は最後のピースにすぎない
system prompt、CLAUDE.md、動的コンテキストについて述べてきたところで、ユーザー入力に目を向けよう。
ユーザー入力はもちろん重要だが、それが単独でモデルに送られるわけではない。
たとえばユーザーがこう言ったとする。
テストを直して。この一文は非常に短く、これだけをモデルに送っても実行可能な情報はほぼない。
しかし Claude Code では、この入力は前述したコンテキスト群とともにモデルの視野に入る。
システムルール:あなたは Claude Code です。ファイルは慎重に変更してください。
プロジェクトメモリ:このプロジェクトは pnpm を使い、テストコマンドは pnpm test です。
Git 状態:現在のブランチには未コミットのファイルが 3 つあります。
ツール説明:Read、Grep、Bash、Edit が使用可能です。
履歴メッセージ:ユーザーが先ほど「ログインテストが失敗している」と言っていました。
現在の入力:テストを直して。このときモデルが理解するのは、孤立した「テストを直して」ではない。
現在のリポジトリ、現在のルール、現在のツールの制約、現在のタスク履歴を踏まえたうえで、
「テストを直す」というエンジニアリングアクションを継続せよ。ユーザー prompt は、むしろ最後のトリガーに近い。Agent に「いま何をすべきか」を伝えるが、それを正しく実行できるかどうかは、その手前にあるコンテキストの組み立てが十分かどうかにかかっている。
8. ツール結果もプロンプトの一部なのか?
これは見落とされがちなポイントです。
プロンプトといえば「モデルに送信する前に書き上げる内容」と考えがちです。しかし Agent Loop においては、ツールの実行結果が次ラウンドのモデル入力の一部になります。
たとえば、第一ラウンドでモデルが次のように判断したとします。
package.json を読みたい。Claude Code が Read ツールを実行し、ファイルの内容を取得します。
このツール結果が messages に書き戻されなければ、次のラウンドのモデルは依然として package.json の中身を知りません。
つまり、ツール結果の書き戻しはプロンプトランタイムの要です。
モデルがアクションの意図を生成
-> ツールシステムが実行
-> ツール結果がメッセージになる
-> 次ラウンドのコンテキストに組み込まれ、モデルに渡されるこのステップによって、外界の事実がモデルにとって可読なコンテキストへと再翻訳されます。
言い換えれば、Claude Code のプロンプトはユーザー入力時に一度だけ組み立てられるのではなく、外界を観測するたびに成長し、刈り込み、再構成されていくのです。
これこそが、エージェントが複数ラウンドにわたって動作し続けられる理由です。
9. 圧縮:コンテキストに収まらないとき、無作為に削除してはいけない
Prompt の組み立てには、もう一つ避けて通れない問題がある。コンテキストウィンドウの上限だ。
エージェントがファイルを読み、テストを実行し、コードを検索し始めると、messages は急速に膨張する。数十ターンも経てば、全履歴をそのまま詰め込んでいたらコストは爆発し、モデルのコンテキスト上限すら超えてしまう。
このとき、圧縮が必須になる。
しかし、圧縮は無作為な削除であってはならない。
Claude Code におけるコンテキストの優先度は、おおむね次のようになっている。
最優先:システムルール、パーミッションルール、プロジェクトメモリ
中程度:直近の会話、現在のタスク状態、最新のツール実行結果
低優先:かなり過去のツール出力、すでに関係なくなった履歴の詳細システムルールとプロジェクトメモリの優先度が高いのはなぜか。
それらはエージェントの行動の境界を決めるものだからだ。
圧縮の過程で「generated/ ディレクトリを変更してはいけない」というルールが消えてしまったら、後続のモデルが危険な変更を加えるかもしれない。「コミットメッセージは日本語で」というルールが消えれば、振る舞いが突然一貫性を失う。
だから、優れた圧縮とは「トークンを少し減らす」ことではない。それは——
限られたウィンドウの中に、次の一手を判断するために最も必要な情報を残すことだ。
圧縮後のサマリーは、そのまま後続の Prompt 組み立てに引き継がれる。モデルは完全な履歴を見ることはできなくても、これまで何をしてきたか、いまどこで行き詰まっているか、次にどう進むべきかを把握できる。
10. チェーン全体を繋ぎ合わせる
Claude Code のプロンプト組み立ては、次の一本のチェーンとして整理できる。
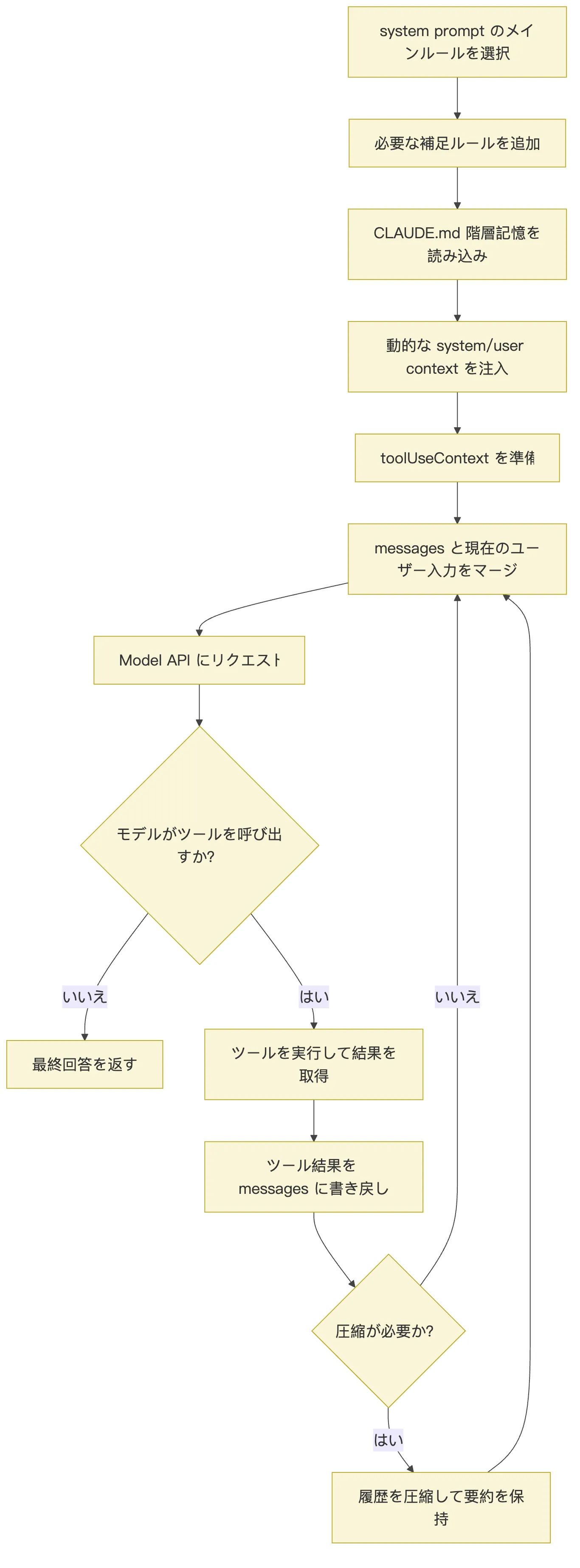
この図には三つの重要なポイントがある。
第一に、システムプロンプトには優先順位があり、すべてのソースが単純に平坦に結合されるわけではない。
第二に、CLAUDE.md、Git の状態、日付、ツールコンテキストといった情報は静的なテンプレートではなく、実行時のコンテキストである。
第三に、ツールの実行結果や圧縮された要約は次のターンの入力に戻され、プロンプトの組み立ては Agent Loop 全体を通じて行われる。
11. 具体例で全体の流れを追う
ユーザーが次のように入力したとします。
帮我修一下登录测试。Claude Code が実際にモデルへ渡すのは、この一文だけではありません。実行現場の情報一式が揃っています。
ステップ1:システムプロンプトの選択
通常の会話ならデフォルトの Claude Code 行動ルール、子 Agent なら Agent 専用プロンプト、コーディネーターモードなら Coordinator プロンプト、override が設定されていればそれが直接使われます。
ステップ2:メモリの読み込み
システムは次のような情報を読み込むかもしれません。
ユーザー級:回答は中国語で。
プロジェクト級:本プロジェクトでは pnpm を使用する。
プロジェクト級:テストコマンドは pnpm test -- --runInBand。
プロジェクト級:generated/ を直接変更しないこと。
ローカル級:ローカルのバックエンドサービスのポートは 4000。ステップ3:動的コンテキストの注入
システムは以下の情報を補完します。
現在のブランチ:feature/login-test
Git ステータス:src/auth/login.ts に未コミットの変更あり
直近のコミット:fix auth redirect
現在の日付:2026-05-02ステップ4:ツールコンテキストの準備
モデルは使用可能なツールを認識します。
Read / Grep / Bash / Edit / Task ...同時に、どのツールに権限が必要か、どの操作が直接実行できないかも把握します。
ステップ5:メッセージ履歴と現在のユーザー入力のマージ
ユーザーが既にエラーメッセージを貼り付けていたり、モデルが直前のテストを走らせていたりする場合、それらはすべて messages の一部として今回のコンテキストに組み込まれます。
ステップ6:モデルが行動を開始する
モデルはまず Grep でログインテストを検索し、Read でテストファイルを確認し、Bash で対象テストを実行し、エラーを確認した上で Edit でソースコードを修正する、といった流れを取るでしょう。
ツールの実行結果は毎回 messages に戻され、Claude Code が次のラウンドのコンテキストを再構築します。
これが、Claude Code が「プロジェクトを理解している」かのように見える理由です。魔法のように理解しているのではなく、毎ラウンド、プロジェクトのルール、実行状態、ツールの観測結果をモデルの前に並べ直しているのです。
12. この仕組みが本当に解決したこと
プロンプト組み立て機構が解決するのは、「プロンプトをもっと長く書く」ことではなく、四つの工学的課題だ。
第一に、振る舞いの一貫性。
システムプロンプトの優先順位によって、異なるモードでもモデルの役割が明確に保たれる。CLAUDE.md の階層化によって、組織ルール・ユーザー設定・プロジェクト規約が安定してコンテキストに取り込まれる。
第二に、タスクへの適合度。
動的コンテキストによって、モデルはカレントディレクトリ・Git 状態・日付・ツールセット・直近の実行結果を把握する。汎用的なルールをあらゆるプロジェクトに当てはめるようなことはしない。
第三に、長時間タスクの継続性。
ツール実行結果が messages に埋め込まれ、圧縮サマリーが次のターンに引き継がれる。エージェントがアクションのたびに記憶喪失になることはない。
第四に、コストとパフォーマンス。
安定セグメントのキャッシュ、動的セグメントの分離、CacheSafeParams の再利用により、複数ターンの呼び出しや子エージェントの fork で毎回プレフィックス全体を再処理する必要がなくなる。
この四点が揃ってこそ、Claude Code のプロンプトエンジニアリングだ。
より正確に言えば、これはもはや従来の意味でのプロンプトエンジニアリングではなく、**コンテキストエンジニアリング(Context Engineering)**である。
この二つの言葉の違いは覚えておく価値がある。プロンプトエンジニアリングは「この一文をどう書けば効果が上がるか」を考え、コンテキストエンジニアリングは「モデルにどの情報を、どんな順序で見せ、どう更新するか」を考える。後者こそが、本番レベルのエージェントに求められる中核的な能力である。
13. ソースコードを読むときのアンカーポイント
今後ソースコードを追いかける場合、まず以下のアンカーポイントを押さえるとよいでしょう。
buildEffectiveSystemPrompt()
-> system prompt の上書き・置換・追加の優先順位を確認
getSystemContext()
-> Git の状態や環境情報がどのようにシステムコンテキストに注入されるかを確認
getUserContext()
-> 日付、CLAUDE.md、ユーザー・プロジェクトメモリがどのように注入されるかを確認
claudemd.ts
-> CLAUDE.md の階層的な検出・解析・マージ・サイズ制限の仕組みを確認
query.ts / QueryEngine
-> 各ターンでリクエストの構築、モデル呼び出し、ツール実行、メッセージの埋め戻しの流れを確認
SYSTEM_PROMPT_DYNAMIC_BOUNDARY
-> 安定セグメントと動的セグメントの境界がどのように分けられ、キャッシュが効くかを確認
CacheSafeParams
-> メインエージェントとサブエージェントがどのようにキャッシュ可能なコンテキストを再利用するかを確認最初からすべての関数名を暗記する必要はありません。むしろ重要なのは、それぞれがどのレイヤーに属しているかを先に把握することです。
system prompt の優先順位:モデルのアイデンティティと振る舞いの基盤を決定
CLAUDE.md メモリ:ユーザーとプロジェクトのルールを決定
system/user context:ランタイムの環境情報を決定
messages:現在のタスク履歴を決定
toolUseContext:モデルが呼び出せる機能を決定
cache/compact:長時間セッションのコストと安定性を決定ここで、もうひとつソースコードに即した読み方のパスを補足します。
まず QueryEngine.submitMessage() から見ていきましょう。1 ターンの開始時に system prompt parts を取得し、デフォルトプロンプト、カスタムプロンプト、メモリプロンプト、追加プロンプトを組み立てて最終的な systemPrompt を構成します。この位置を見ると、Prompt が独立したモジュールではなく、セッションオーケストレーションの一部であることがわかります。
次に fetchSystemPromptParts() を見ます。これは入力を 3 つに分解します。
defaultSystemPrompt:Claude Code の基本的な操作マニュアル
userContext:ユーザールール、プロジェクトルール、日付などのコンテキスト
systemContext:Git の状態などのランタイム環境スナップショットこれら三種類のものはライフサイクルが異なるため、ひとつの大きなテキストブロックに混ぜるわけにはいきません。
次に constants/prompts.ts を見てみましょう。ここで最も重要なのは、特定のプロンプト文がどれほど巧みに書かれているかではなく、string[] で system prompt をセグメントに分割して返し、SYSTEM_PROMPT_DYNAMIC_BOUNDARY によって静的にキャッシュ可能なプレフィックスと動的なセッション末尾を分離している点です。この境界は、Prompt もコストシステムの一部であることを示しています。安定したセグメントは可能な限り再利用し、動的なセグメントはセッションごとに変化させる、という設計です。
最後に query.ts に戻ります。Prompt が組み立てられた後、それが単独でモデルに送られることはありません。messagesForQuery、ツールスキーマ、systemContext、ツール結果のバジェット、圧縮済みの履歴とともに、このターンのモデル入力を構成します。
したがって、ソースコードレベルでの Prompt Runtime は次のように整理できます。
QueryEngine がこのターンで取得すべき prompt parts を決定する
fetchSystemPromptParts がデフォルトルール、ユーザーコンテキスト、環境スナップショットを分割する
constants/prompts.ts がシステム操作マニュアルとキャッシュ境界を担当する
query.ts が prompt、messages、ツール、コンテキストをまとめてモデルに送り込む14. 最後に一言で締めくくる
Claude Code のプロンプトは「魔法の呪文」ではない。
むしろ、毎ラウンドごとに整え直される作業台に近い:
左側にシステムルール、
右側にプロジェクトメモリ、
中央に現在のタスク、
脇にツールを並べ、
机が散らかれば圧縮して整理し、
次に作業を再開するときにもう一度並べ直す。この動的組み立て機構こそが、Claude Code を単なるチャットボックスからエンジニアリング Agent へと変える鍵である。
前回の ReAct 編が「Agent がどのようにラウンドを重ねて行動するか」を扱ったのに対し、今回の Prompt Runtime 編が扱うのは:
毎ラウンドの行動の前に、Claude Code がモデルに見せるべき世界をどのように整え直すかである。